
The AI project "Linly," led by Professor Shen Linlin's team at the National Engineering Laboratory for Big Data System Computing Technology, has previously released Chinese transfer versions based on models such as LLaMA-1 and Falcon. Recently, the team conducted Chinese training and quality evaluation on LLaMA-2, and has now released Chinese-LLaMA2 7B and 13B versions. Let's take a look!
1. Project Introduction
As large-scale language models demonstrate enormous application potential in numerous fields, foundational models have become a focus of attention. Recently, many institutions have released Chinese foundational models, such as GLM and baichuan. These models utilize significant computing power, and their public release provides great convenience for community researchers.
Meanwhile, many representative models are primarily trained in English (e.g., LLaMA-1 & 2, Falcon). While they are powerful in English, their cross-language performance is relatively weak. To provide the community with more model options and training solutions for other less commonly taught languages, Professor Shen Linlin, Deputy Director of the National Engineering Laboratory for Big Data System Computing Technology and Director of the Institute of Computer Vision at the School of Computer Science and Software Engineering, Shenzhen University, led the "Lingli" project team to propose a cross-language transfer method. Based on a pre-trained English language model, this method uses significantly less computation than pre-training from scratch to incrementally train on Chinese corpora and align with English knowledge, resulting in a high-performance Chinese model.
Prior to this, the "Lingli" project team had already released Chinese transfer versions based on models such as LLaMA-1 and Falcon. Recently, the team conducted Chinese localization training and quality evaluation on LLaMA-2, and has currently released Chinese-LLaMA2 7B and 13B versions.
Model download address: https://github.com/CVI-SZU/Linly
Huggingface online demo: https://huggingface.co/spaces/Linly-AI/Linly-ChatFlow
2. Training Scheme
Previous dialogue model training typically distinguished between a language model training phase and an instruction fine-tuning phase. To simplify the training process, quickly transfer knowledge to the model, and enhance its Chinese capabilities, the project team used mixed data from different data sources for training Chinese-LLaMA2.
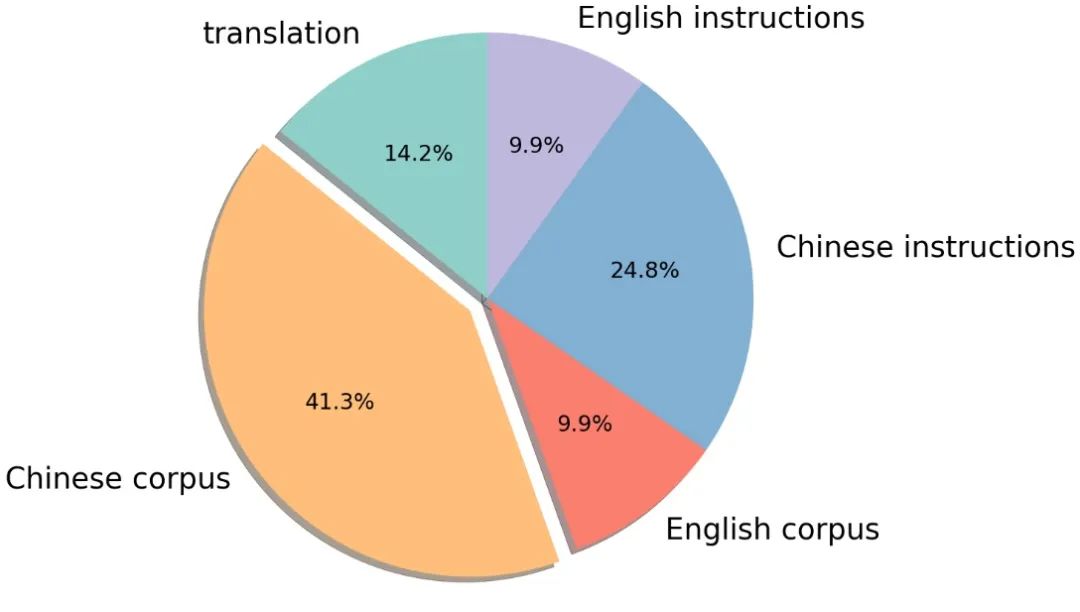
The unsupervised corpus includes general corpora such as Chinese encyclopedias, scientific literature, community Q&A, and news, providing knowledge of the Chinese world; the English corpus includes datasets such as SlimPajama and RefinedWeb, used to balance the distribution of training data and prevent the model from forgetting existing knowledge; and parallel Chinese and English corpora are used to align the representations of the Chinese and English models, quickly transferring the knowledge learned by the English model to Chinese.
Supervised data includes instruction datasets built based on self-instructions, such as BELLE, Alpaca, Baize, and InstructionWild; and datasets built using manually generated prompts, such as FLAN, COIG, Firefly, and pCLUE. The distribution of the corpora is shown in the figure:
3. Vocabulary Expansion and Initialization
LLaMA-2 uses the same vocabulary as LLaMA-1, thus still facing the problem of insufficient Chinese vocabulary. In Linly-LLaMA-2, 8076 commonly used Chinese characters and punctuation marks are directly added. The average value of these Chinese characters at the corresponding token positions in the original vocabulary is used as the initialization value in the model's embedding and target layers.
4. Model Training
During the training phase, Alpaca format is used as the instruction delimiter, randomly shuffling all data and fine-tuning the model with all parameters. Furthermore, a curriculum learning training strategy is used, employing more English and parallel corpora in the early stages of training, gradually increasing the proportion of Chinese data as the training steps increase. This provides a smooth learning path for the model training, contributing to convergence stability. Training is based on the TencentPretrain pre-training framework, using a 5e-5 learning rate, cosine scheduler, 2048 sequence length, 512 batch size, BF16 precision, and deepspeed zero2 for training.
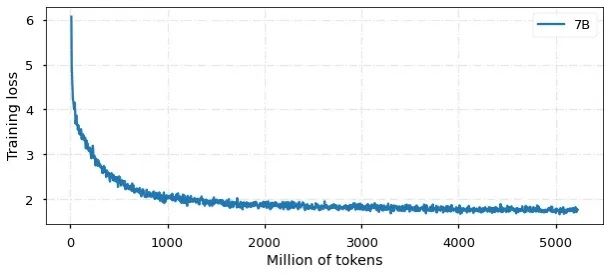
Currently, the model has been trained with 5 billion Chinese and English tokens, and the convergence result is shown in the figure:
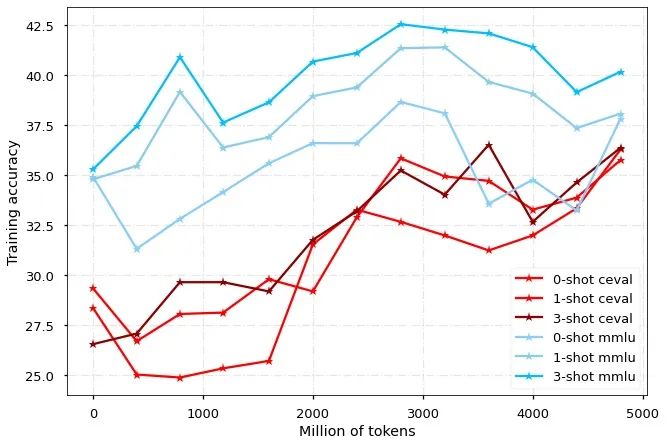
The model was evaluated on the MMLU and CEVAL leaderboards for English and Chinese respectively. It can be seen that the Chinese-LLaMA2 model can quickly improve Chinese performance without sacrificing English performance.
5. Generate Examples
5.1 Knowledge Q&A

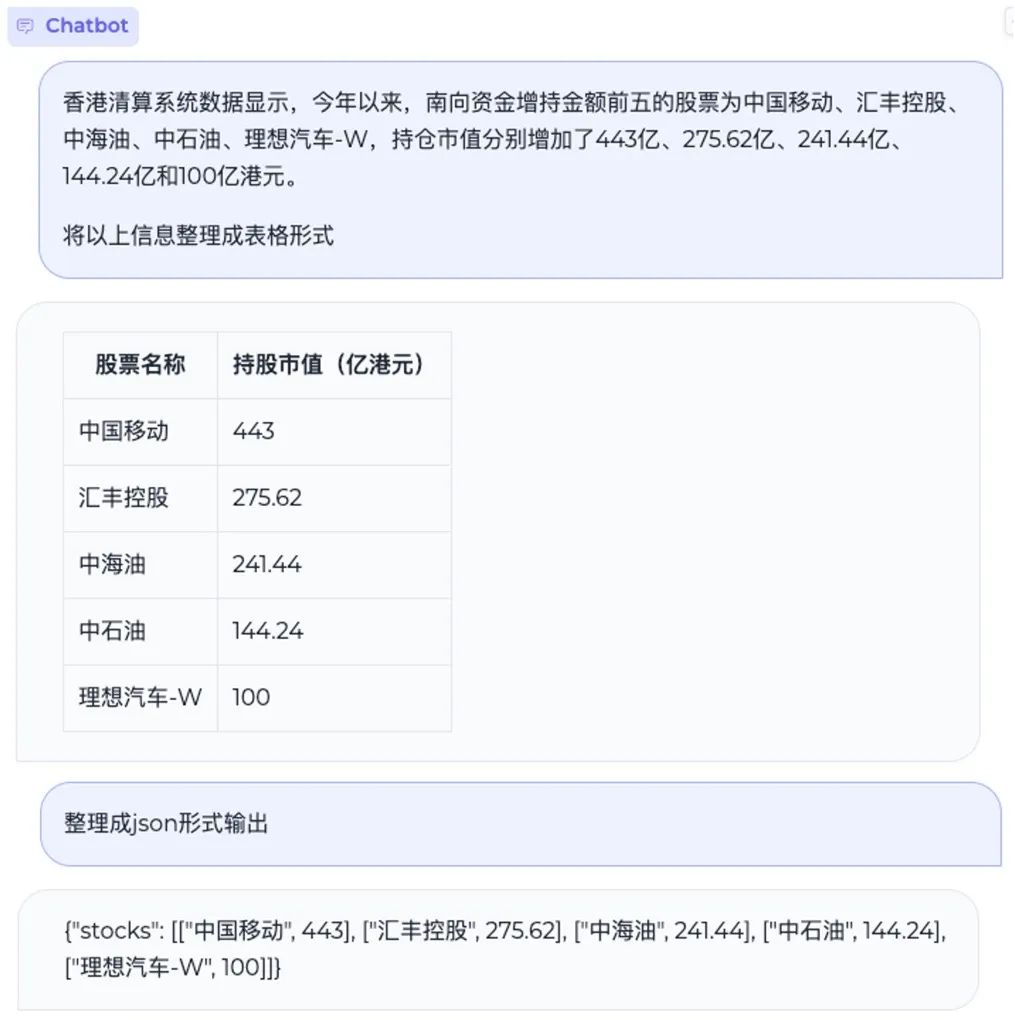
5.2 Information Extraction
5.3 Code Generation







